스토리지 풀 수리 작업이 중단됩니다.
디스크 두 개를 레이드1으로 사용하고 있습니다. 디스크 한 개가 고장나서 교체 한 뒤 수리를 진행하는데요. 수리 작업이 중단됩니다.
교체하지 않은 디스크에서 데이터를 읽지 못해서 발생하는 증상인데요. 디스크에 배드섹터가 존재 하더라도 배드섹터에 읽기/쓰기 작업을 하기 전에는 배드섹터의 존재를 알지 못합니다. 수리 작업을 하려면 읽기 작업이 발생하고 그제야 배드섹터의 존재를 알아차리게 됩니다. 하지만 데이터를 읽을 수 없으므로 수리 작업은 진행되지 않습니다.
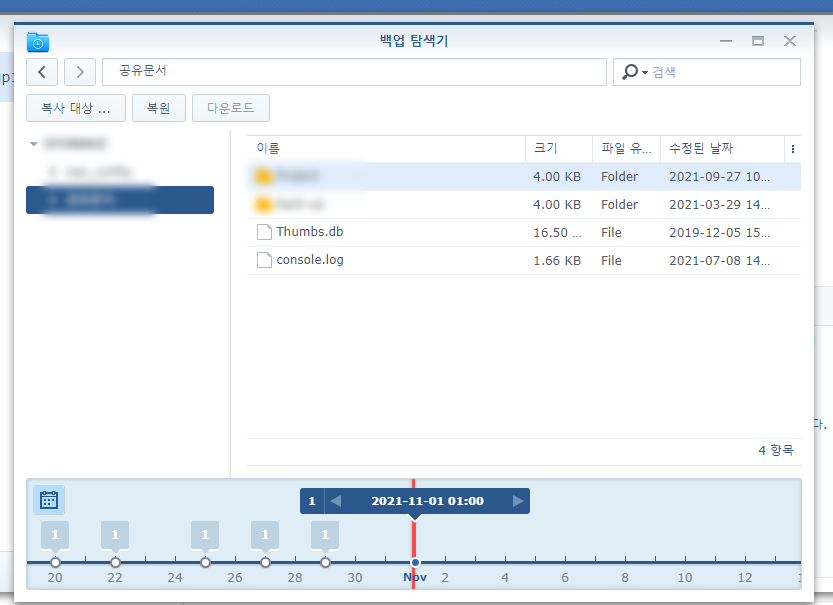
다행히 하이퍼 백업을 사용하고 있어서 하이퍼 백업으로 데이터를 복원했습니다.
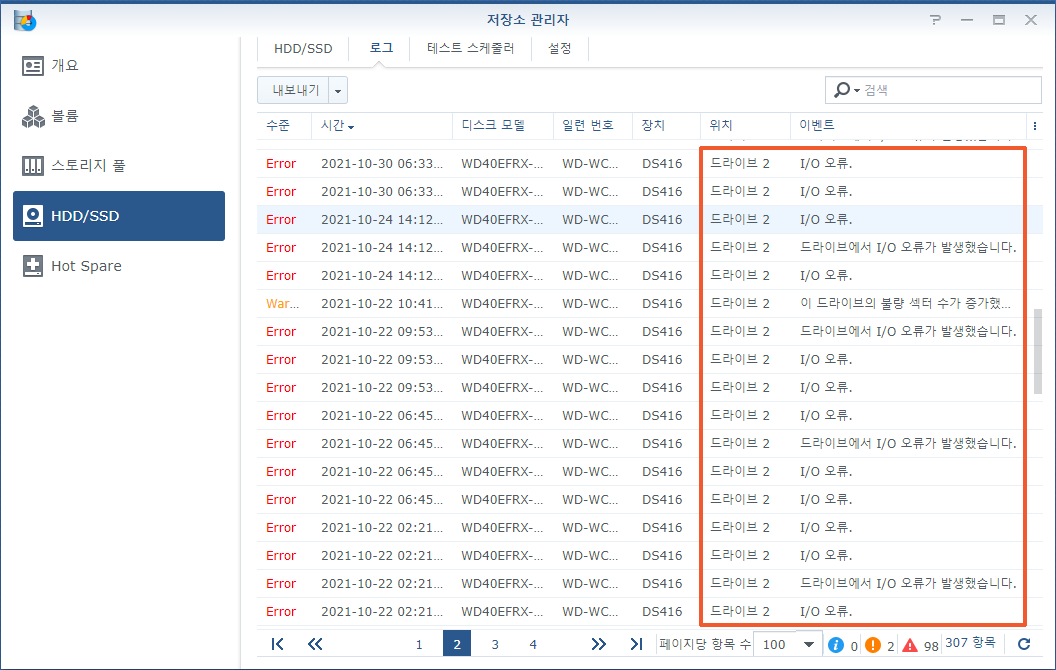
2번 디스크에서 오류가 발생합니다. I/O 오류. 드라이브에서 I/O 오류가 발생했습니다. 이 드라이브의 불량 섹터 수가 증가했습니다.
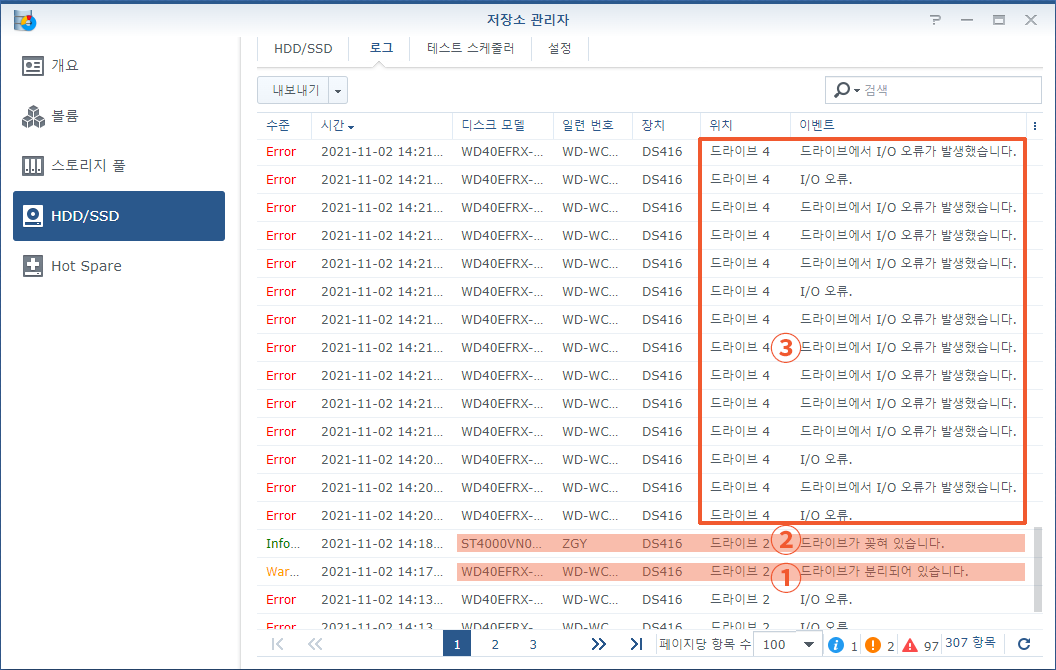
① 2번 디스크(WD RED 4TB)를 교체 합니다. “드라이브가 분리되어 있습니다.”라는 기록이 생성됩니다.
② 새 디스크(씨게이트 아이언울프 4TB)를 장착합니다. “드라이브가 꽂혀 있습니다.”라는 기록이 생성됩니다.
③ 4번 디스크의 데이터를 읽어서 2번 디스크에 기록해야 하는데요. 4번 디스크에서 데이터를 읽지 못합니다.
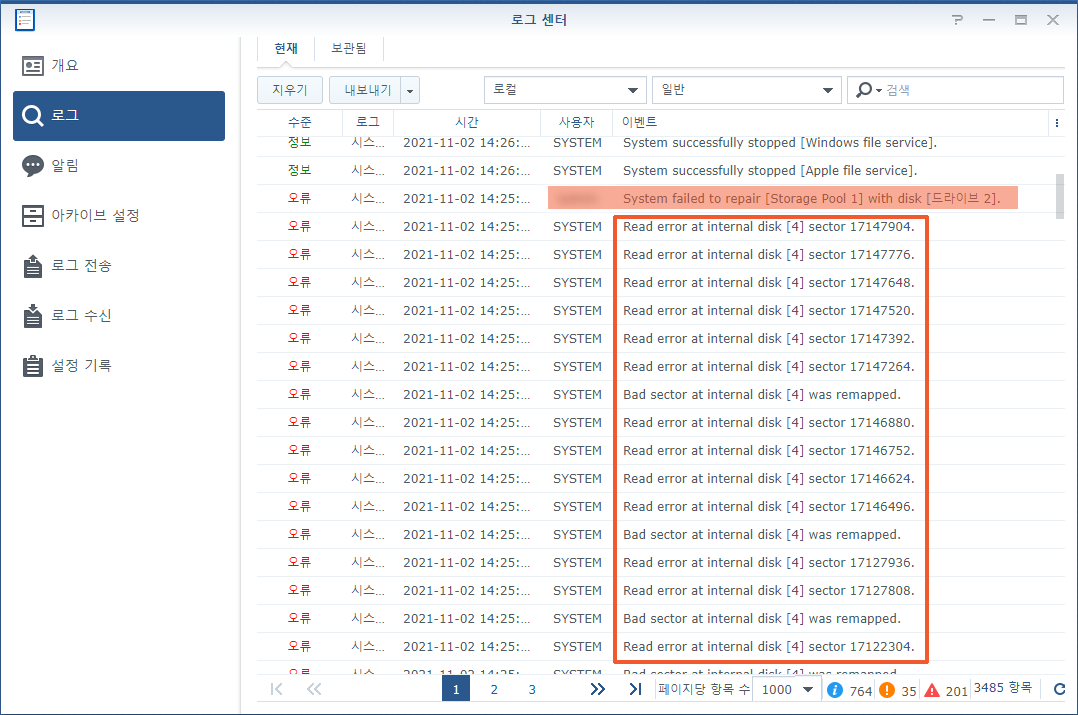
수리 작업이 5분 정도 진행되다가 결국에는 중단됩니다. “System failed to repair [Storage Pool 1] with disk [드라이브 2]”라는 기록이 생성됩니다.
하이퍼 백업으로 복원합니다.
두 개의 디스크를 레이드1으로 사용하지만 두 개의 디스크가 모두 고장났으므로 기존 스토리지 풀은 더 이상 사용할 수 없습니다. 새로운 스토리지 풀을 만드는 것에서 시작해서 볼륨 생성, 공유 폴더 생성, 패키지 설치 등 모든 작업을 다시 해야 합니다.
DS416은 4베이 모델입니다. 디스크 2개는 레이드1으로 사용하고 나머지 디스크는 하이퍼 백업의 데이터를 저장하는 용도로 사용했습니다. 5년 만에 하이퍼 백업의 혜택을 보게 되었습니다.

하이퍼 백업으로 복원을 완료했습니다. 1.6TB 정도의 용량을 복원하는데 소요된 시간은 7시간 정도입니다.
디스크를 교체하는 순간부터 수리 작업이 실패하기까지의 과정이 /var/log/messages 파일에 기록되어 있습니다.
- WD 디스크 제거.
- 씨게이트 디스크 장착.
- 씨게이트 디스크에 파티션 생성.
- md0(DSM 설치한 파티션 ) 복제 완료. md1(스왑파티션) 복제 완료.
- md2(스토리지 풀에 사용한 파티션) 복제하는 도중에 4번 디스크의 섹터를 읽을 수 없는 상황이 계속 발생 함.
- 수리 작업을 포기하고 씨게이트 디스크를 레이드에서 제외 시킴.
2021-11-02T14:16:53+09:00 NAS synoscgi_SYNO.Core.Storage.Disk_1_deactivate_disk[5677]: raid_disk_deactivate.c:72 /dev/sdb (SN:WD-WC**********) has been deactivated
2021-11-02T14:17:26+09:00 NAS hotplugd: hotplugd.c:1592 ==== SATA disk [sdb] hotswap [remove] ====
2021-11-02T14:18:13+09:00 NAS hotplugd: hotplugd.c:1592 ==== SATA disk [sdb] hotswap [add] ====
2021-11-02T14:18:14+09:00 NAS hotplugd: hotplugd.c:1627 ==== SATA disk [sdb] Model: [ST4000VN008-2DR166] ====
2021-11-02T14:18:14+09:00 NAS hotplugd: hotplugd.c:1628 ==== SATA disk [sdb] Serial number: [ZGY*****] ====
2021-11-02T14:18:14+09:00 NAS hotplugd: hotplugd.c:1629 ==== SATA disk [sdb] Firmware version: [SC60] ====
2021-11-02T14:18:40+09:00 NAS synoscgi_SYNO.Storage.CGI.Volume_1_repair[10576]: space_disk_sys_partition_create_join.c:160 [Info] Create system partition of disk path ‘/dev/sdb’, diskID.cnr=1
2021-11-02T14:18:40+09:00 NAS kernel: [6616590.974911] md: md0: current auto_remap = 0
2021-11-02T14:18:40+09:00 NAS kernel: [6616590.979297] md: recovery of RAID array md0
2021-11-02T14:18:40+09:00 NAS synoscgi_SYNO.Storage.CGI.Volume_1_repair[10576]: space_disk_data_partition_clean.c:44 [Info] Clean data partition on /dev/sdb
2021-11-02T14:18:40+09:00 NAS kernel: [6616591.203010] md: md1: current auto_remap = 0
2021-11-02T14:18:40+09:00 NAS kernel: [6616591.207395] md: recovery of RAID array md1
2021-11-02T14:18:41+09:00 NAS synoscgi_SYNO.Storage.CGI.Volume_1_repair[10615]: space_disk_data_partition_create.c:178 [Info] Clean data partition on [/dev/sdb]
2021-11-02T14:18:41+09:00 NAS synoscgi_SYNO.Storage.CGI.Volume_1_repair[10615]: space_disk_data_partition_create.c:182 [Info] Create primary data partition on [/dev/sdb]
2021-11-02T14:18:43+09:00 NAS kernel: [6616593.617662] md: md2: set sdb3 to auto_remap [1]
2021-11-02T14:18:43+09:00 NAS kernel: [6616593.622376] md: md2: set sdd3 to auto_remap [1]
2021-11-02T14:19:26+09:00 NAS kernel: [6616636.605101] md: md1: recovery done.
2021-11-02T14:19:26+09:00 NAS kernel: [6616636.611882] md: md1: current auto_remap = 0
2021-11-02T14:19:36+09:00 NAS kernel: [6616646.433699] md: md0: recovery done.
2021-11-02T14:19:36+09:00 NAS kernel: [6616646.444065] md: md0: current auto_remap = 0
2021-11-02T14:19:36+09:00 NAS kernel: [6616646.444447] md: recovery of RAID array md2
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.588039] ata4.00: exception Emask 0x0 SAct 0x60000003 SErr 0x0 action 0x0
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.595247] ata4.00: irq_stat 0x40000000
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.599353] ata4.00: failed command: READ FPDMA QUEUED
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.604661] ata4.00: cmd 60/00:e8:00:28:05/04:00:01:00:00/40 tag 29 ncq 524288 in
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.620713] ata4.00: status: { DRDY ERR }
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.624919] ata4.00: error: { UNC }
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.644404] sdd3 auto_remap 1
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.688469] Descriptor sense data with sense descriptors (in hex):
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.722152] end_request: I/O error, dev sdd, sector in range 17113088 + 0-2(12)
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.729626] drivers/md/raid1.c:end_sync_read(2174) BIO_AUTO_REMAP detected
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.736664] report md[2] auto-remapped sector:[7676288]
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.742055] read error, md2, sdd3 index [3], sector 17115648 [end_sync_read]
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.749276] read error, md2, sdd3 index [3], sector 17115776 [end_sync_read]
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.756496] read error, md2, sdd3 index [3], sector 17115904 [end_sync_read]
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.763707] read error, md2, sdd3 index [3], sector 17116032 [end_sync_read]
2021-11-02T14:20:41+09:00 NAS kernel: [6616711.770925] read error, md2, sdd3 index [3], sector 17116160 [end_sync_read]
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.884189] ata4.00: exception Emask 0x0 SAct 0x40000000 SErr 0x0 action 0x0
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.891414] ata4.00: irq_stat 0x40000000
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.895506] ata4.00: failed command: READ FPDMA QUEUED
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.900827] ata4.00: cmd 60/08:f0:10:a3:05/00:00:01:00:00/40 tag 30 ncq 4096 in
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.916710] ata4.00: status: { DRDY ERR }
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.920884] ata4.00: error: { UNC }
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.942884] sdd3 auto_remap 1
2021-11-02T14:25:11+09:00 NAS kernel: [6616981.986961] Descriptor sense data with sense descriptors (in hex):
2021-11-02T14:25:11+09:00 NAS kernel: [6616982.020648] end_request: I/O error, dev sdd, sector in range 17145856 + 0-2(12)
2021-11-02T14:25:11+09:00 NAS kernel: [6616982.028998] md/raid1:md2: sdd: unrecoverable I/O read error for block 7707392
2021-11-02T14:25:11+09:00 NAS kernel: [6616982.029002] md/raid1:md2: mard disk error on sdd3 due to unrecoverable sync read error
2021-11-02T14:25:11+09:00 NAS kernel: [6616982.029006] md/raid1:md2: remove sdb3 from raid due to unrecoverable sync read error
2021-11-02T14:25:12+09:00 NAS kernel: [6616983.372492] SynoCheckRdevIsWorking (10363): remove active disk sdb3 from md2 raid_disks 2 mddev->degraded 1 mddev->level 1
2021-11-02T14:25:12+09:00 NAS kernel: [6616983.383791] syno_md_error: sdb3 has been removed
2021-11-02T14:25:12+09:00 NAS kernel: [6616983.388583] raid1: Disk failure on sdb3, disabling device.
2021-11-02T14:25:13+09:00 NAS kernel: [6616983.398920] syno_hot_remove_disk (10258): cannot remove active disk sdb3 from md2 … rdev->raid_disk 1 pending 17
2021-11-02T14:25:14+09:00 NAS kernel: [6616984.415619] SynoCheckRdevIsWorking (10363): remove active disk sdb3 from md2 raid_disks 2 mddev->degraded 1 mddev->level 1
2021-11-02T14:25:14+09:00 NAS kernel: [6616984.426924] syno_hot_remove_disk (10258): cannot remove active disk sdb3 from md2 … rdev->raid_disk 1 pending 13
2021-11-02T14:25:15+09:00 NAS kernel: [6616985.445650] SynoCheckRdevIsWorking (10363): remove active disk sdb3 from md2 raid_disks 2 mddev->degraded 1 mddev->level 1
2021-11-02T14:25:15+09:00 NAS kernel: [6616985.456939] syno_hot_remove_disk (10258): cannot remove active disk sdb3 from md2 … rdev->raid_disk 1 pending 13
2021-11-02T14:25:16+09:00 NAS kernel: [6616986.476104] SynoCheckRdevIsWorking (10363): remove active disk sdb3 from md2 raid_disks 2 mddev->degraded 1 mddev->level 1
2021-11-02T14:25:16+09:00 NAS kernel: [6616986.487394] syno_hot_remove_disk (10258): cannot remove active disk sdb3 from md2 … rdev->raid_disk 1 pending 13
2021-11-02T14:25:17+09:00 NAS kernel: [6616987.505607] SynoCheckRdevIsWorking (10363): remove active disk sdb3 from md2 raid_disks 2 mddev->degraded 1 mddev->level 1
2021-11-02T14:25:17+09:00 NAS kernel: [6616987.516913] syno_hot_remove_disk (10258): cannot remove active disk sdb3 from md2 … rdev->raid_disk 1 pending 13
2021-11-02T14:25:47+09:00 NAS kernel: [6617017.896371] md: md2: recovery stop due to MD_RECOVERY_INTR set.
2021-11-02T14:25:47+09:00 NAS kernel: [6617017.902898] md: md2: set sdb3 to auto_remap [0]
2021-11-02T14:25:47+09:00 NAS kernel: [6617017.907616] md: md2: set sdd3 to auto_remap [0]
2021-11-02T14:25:47+09:00 NAS kernel: [6617018.173414] syno_hot_remove_disk (10263): successfully remove active disk sdb3 from md2
2021-11-02T14:25:52+09:00 NAS synoscgi_SYNO.Storage.CGI.Volume_1_repair[10576]: space_repair.c:193 RAID ‘/dev/md2’ rebuilding err. Stop waiting
2021-11-02T14:25:52+09:00 NAS synoscgi_SYNO.Storage.CGI.Volume_1_repair[10576]: space_lib.cpp:1562 failed to repair space: /dev/md2 [0x2000 virtual_space_layer_get.c:97]
2021-11-02T14:25:59+09:00 NAS synostoraged: hotspare_log_repair_err.c:32 [INFO] space [/dev/md2] is not degrade, skip repairing with spare disks
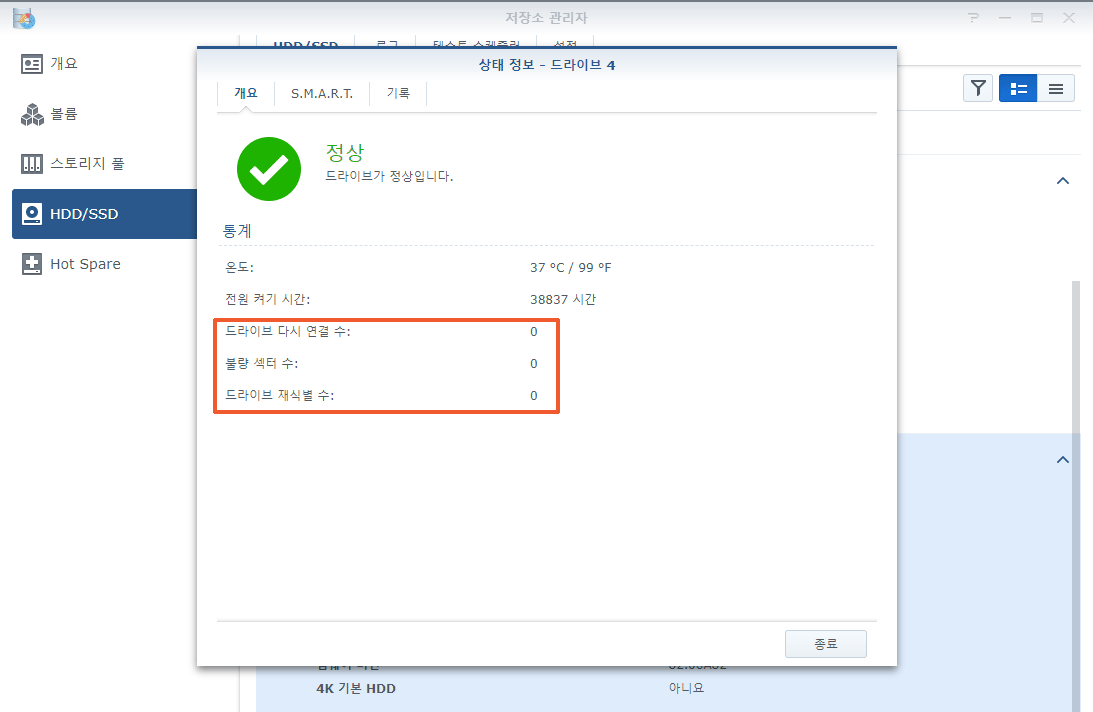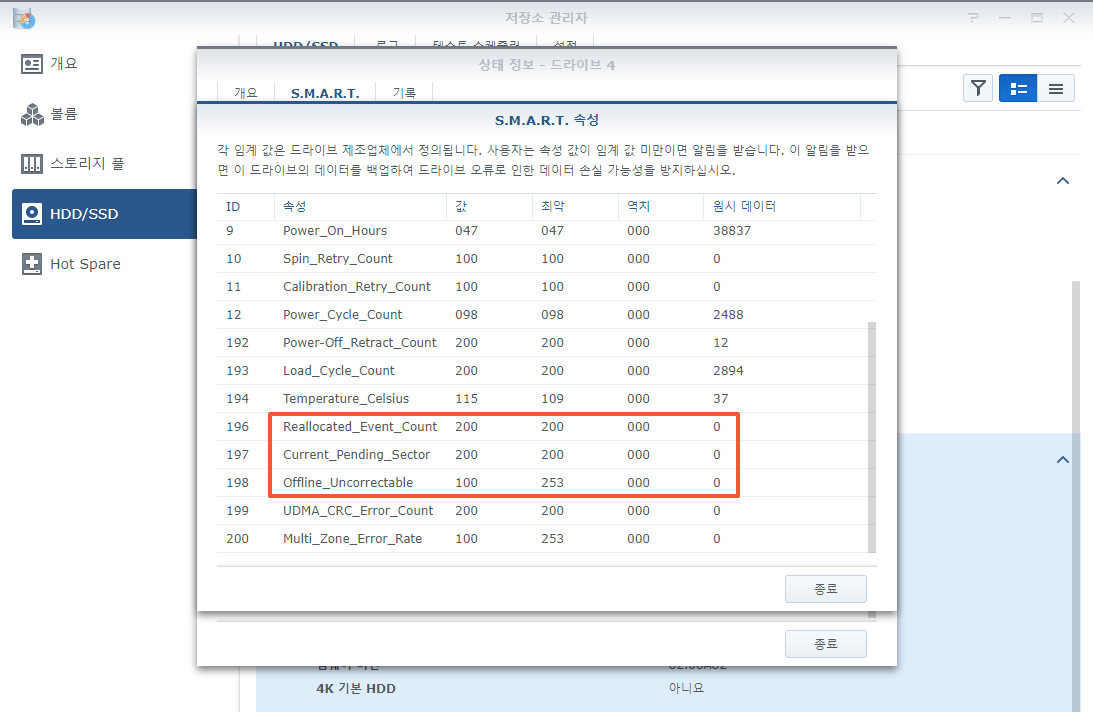
디스크를 교체하는 작업이 중단되는 경우가 종종 발생합니다. 그래서 디스크를 교체 할 때는 디스크를 제거하기 전에 미리 데이터 백업을 해 놓는게 좋습니다.
이번 경우는 하이퍼 백업으로 별도의 디스크에 매일 백업을 하고, 또 4번 디스크의 SMART 값에 배드섹터가 하나도 없다고 나와서 마음 편하게 교체 작업을 진행했습니다.
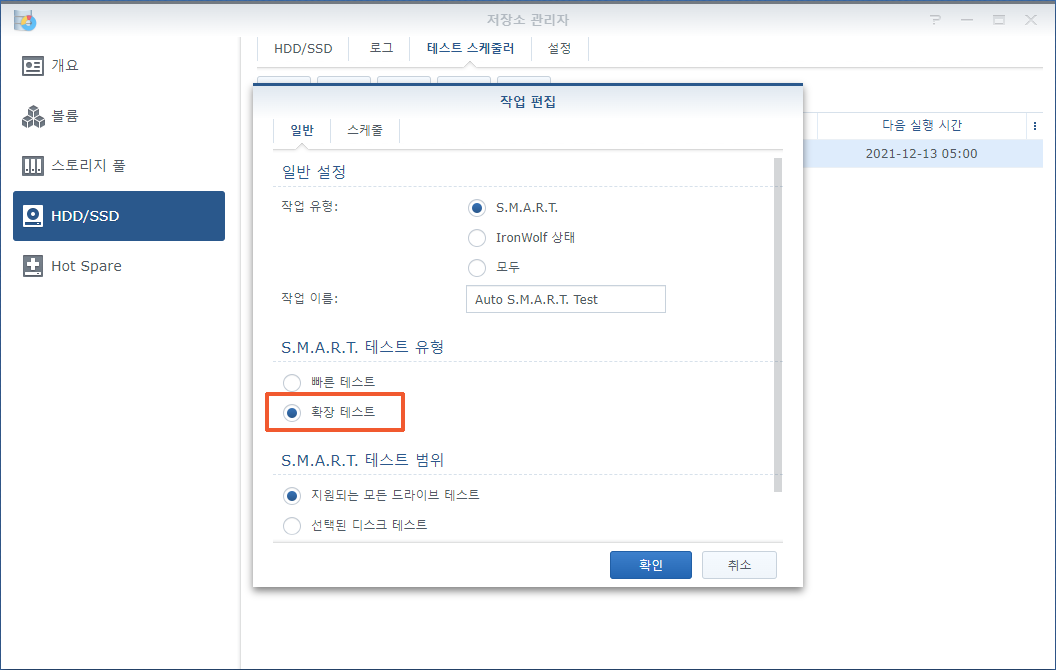
SMART 값이 디스크의 상태를 항상 정확하게 알려주지는 않습니다. 디스크의 상태를 좀 더 정확하게 파악 하려면 주기적으로 ‘SMART 확장 테스트’를 해 주는 게 도움이 됩니다.