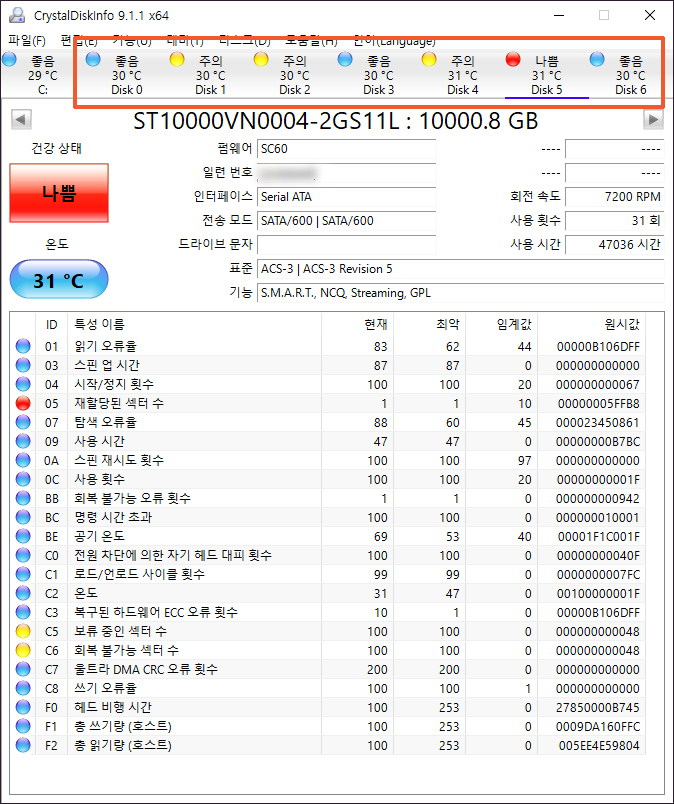
CrystalDiskInfo에서 디스크 세 개만 상태가 “좋음”으로 나옵니다. 나머지 디스크 네 개는 “주의”와 “나쁨”인데요. “좋음”이 아닌 이유는 배드섹터가 발생했기 때문입니다.
레이드로 묶은 디스크에서 배드섹터가 발생하면 그 디스크는 레이드에서 제외됩니다. 레이드 5는 디스크 한 개가 제외되더라도 나스에 저장한 파일을 계속 사용할 수 있습니다. 만약 그 상태에서 또 다른 디스크가 제외되면 파일이 보이지 않게 됩니다. 이 나스는 “주의”와 “나쁨”인 디스크 네 개 중에서 두 개가 레이드에서 제외되었고 그로 인해 파일이 보이지 않는 상황입니다.
소요시간 : 20일 어려움 : ★★★★★
데이터 복구하기. 하드디스크 교체하기.
데이터 복구를 진행합니다. 복구된 파일 개수는 2천 8백만 개입니다. 디스크의 읽기 속도가 느려서 복구작업이 예상보다 오래 걸렸습니다.
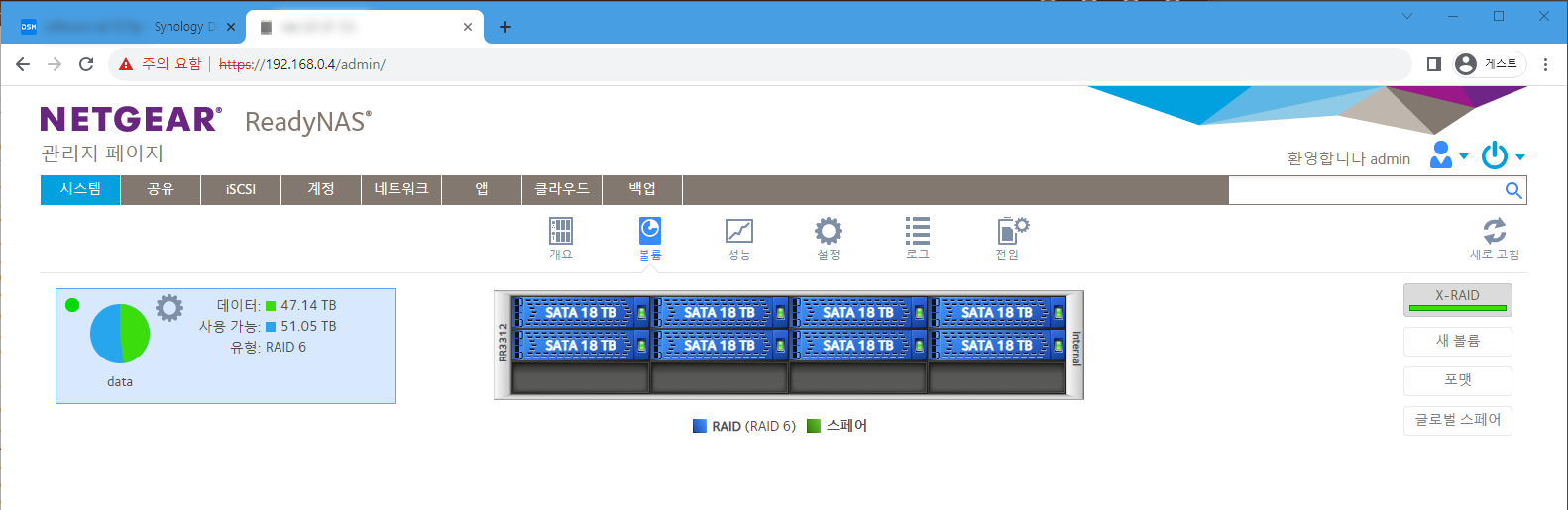
하드디스크를 모두 교체합니다. 볼륨의 용량을 90% 정도 사용했으므로 이참에 용량도 확장합니다. 18TB 디스크를 8개 장착하고 레이드 6를 사용합니다. 볼륨의 크기가 98TB 되는데요. 복구한 데이터 50TB를 넣어도 여유 공간이 충분하게 남습니다.
나스의 설정값(IP주소, 아이디와 비밀번호, 공유 폴더 이름, 공유 폴더 권한)을 기존과 동일하게 셋팅합니다. 설정을 똑같게 잡으면 나스를 설치하고 곧바로 나스 사용이 가능합니다.
공유 폴더 접속시 암호는 /var/lib/samba 디렉토리의 파일을 기존 파일(10TB 디스크의 /var/lib/samba 디렉토리의 파일)로 교체하면 기존 암호를 그대로 사용할 수 있습니다.
디스크와 볼륨에 대한 로그
[23/07/11 01:00:19 KST] warning:volume:LOGMSG_HEALTH_VOLUME_WARN Volume data is Degraded.
[23/07/11 02:58:53 KST] warning:disk:LOGMSG_SMART_REALLOC_SECT_30DAYS_WARN Detected increasing reallocated sector count: [5272] on disk 5 (Internal) [ST10000VN0004-2GS11L ZJV0YYYY] 185 times in the past 30 days. This condition often indicates an impending failure. Be prepared to replace this disk to maintain data redundancy.
[23/07/11 19:27:20 KST] warning:disk:LOGMSG_SMART_REALLOC_SECT_30DAYS_WARN Detected increasing reallocated sector count: [504] on disk 2 (Internal) [ST10000VN0008-2JJ101 ZJV0ZZZZ] 26 times in the past 30 days. This condition often indicates an impending failure. Be prepared to replace this disk to maintain data redundancy.
[23/07/11 20:25:03 KST] notice:disk:LOGMSG_ZFS_DISK_STATUS_CHANGED Disk in channel 2 (Internal) changed state from RESYNC to ONLINE.
[23/07/11 20:28:17 KST] notice:disk:LOGMSG_ZFS_DISK_STATUS_CHANGED Disk in channel 2 (Internal) changed state from ONLINE to RESYNC.
[23/07/11 20:31:39 KST] warning:disk:LOGMSG_SMART_REALLOC_SECT_30DAYS_WARN Detected increasing reallocated sector count: [36528] on disk 6 (Internal) [ST10000VN0004-2GS11L ZJV0XXXX] 2323 times in the past 30 days. This condition often indicates an impending failure. Be prepared to replace this disk to maintain data redundancy.
[23/07/11 20:31:39 KST] warning:disk:LOGMSG_SMART_ATA_ERR_30DAYS_WARN Detected increasing ATA error count: [2367] on disk 6 (Internal) [ST10000VN0004-2GS11L, ZJV0XXXX] 353 times in the past 30 days. This condition often indicates an impending failure. Be prepared to replace this disk to maintain data redundancy.
[23/07/11 20:31:49 KST] notice:volume:LOGMSG_RESILVERCOMPLETE_VOLUME Volume data is resynced.
[23/07/11 20:31:50 KST] warning:volume:LOGMSG_HEALTH_VOLUME Volume data health changed from Degraded to Dead.
[23/07/11 20:31:51 KST] notice:disk:LOGMSG_ZFS_DISK_STATUS_CHANGED Disk in channel 2 (Internal) changed state from RESYNC to ONLINE.
[23/07/11 20:31:51 KST] err:disk:LOGMSG_ZFS_DISK_STATUS_CHANGED Disk in channel 6 (Internal) changed state from ONLINE to FAILED.
[23/07/12 01:00:47 KST] warning:volume:LOGMSG_HEALTH_VOLUME_WARN Volume data is Dead.
/var/log/frontview/status.log 파일의 내용입니다. 수 개월 전부터 disk 2, disk 5, disk 6에서 배드섹터가 발행했고 그로 인해 “Detected increasing ATA error count”, “Detected increasing reallocated sector count” 항목이 무수히 많이 기록되어 있습니다.