| 수준 | 로그 | 시간 | 사용자 | 이벤트 |
|---|
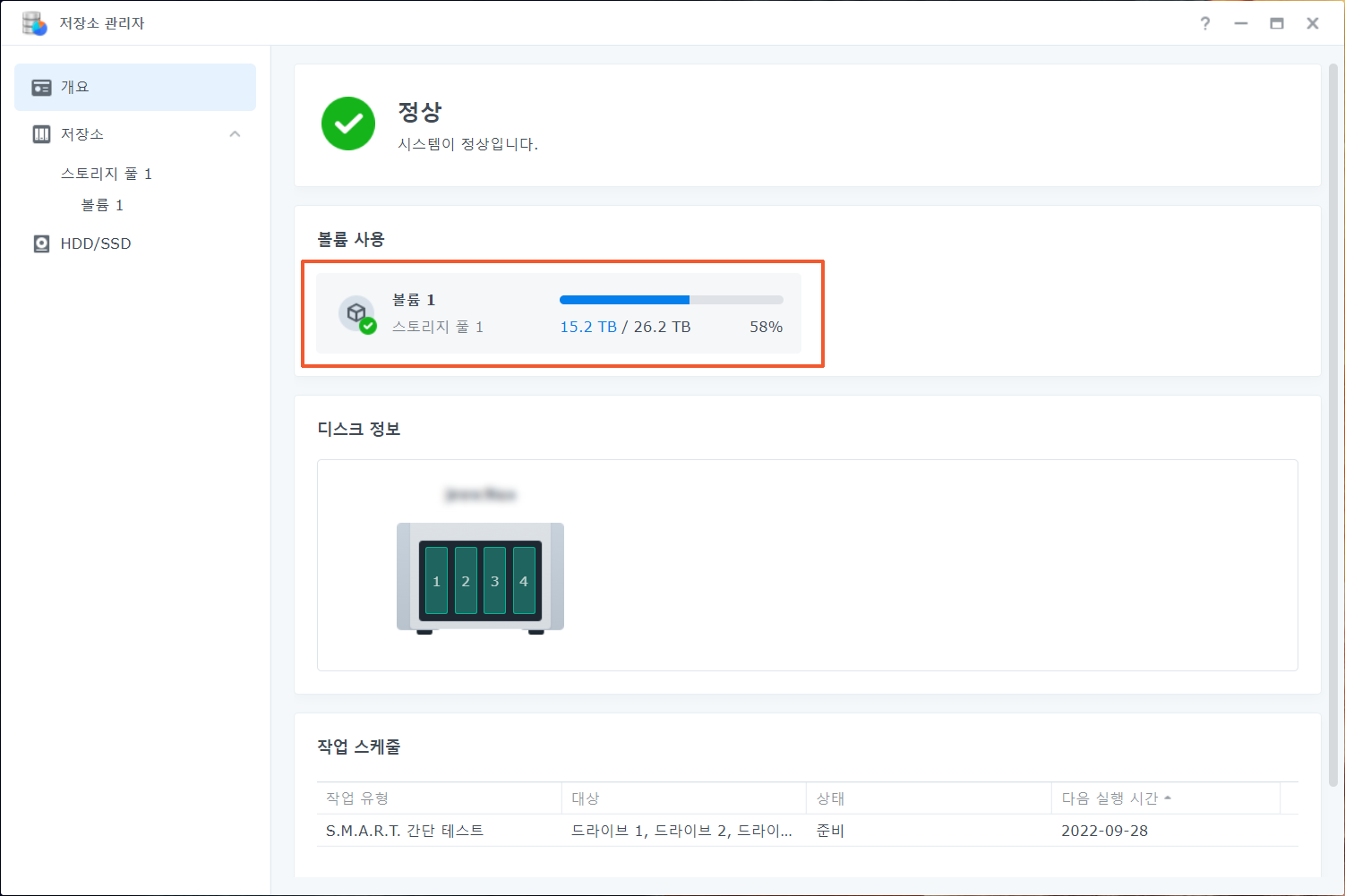
| 정보 | 시스템 | 2022/09/08 04:03:56 | admin | ④System successfully repaired [Storage Pool 1] with drive [Drive 4]. |
| 정보 | 시스템 | 2022/09/07 11:56:31 | admin | ③System started to repair [Storage Pool 1] with [Drive 4]. |
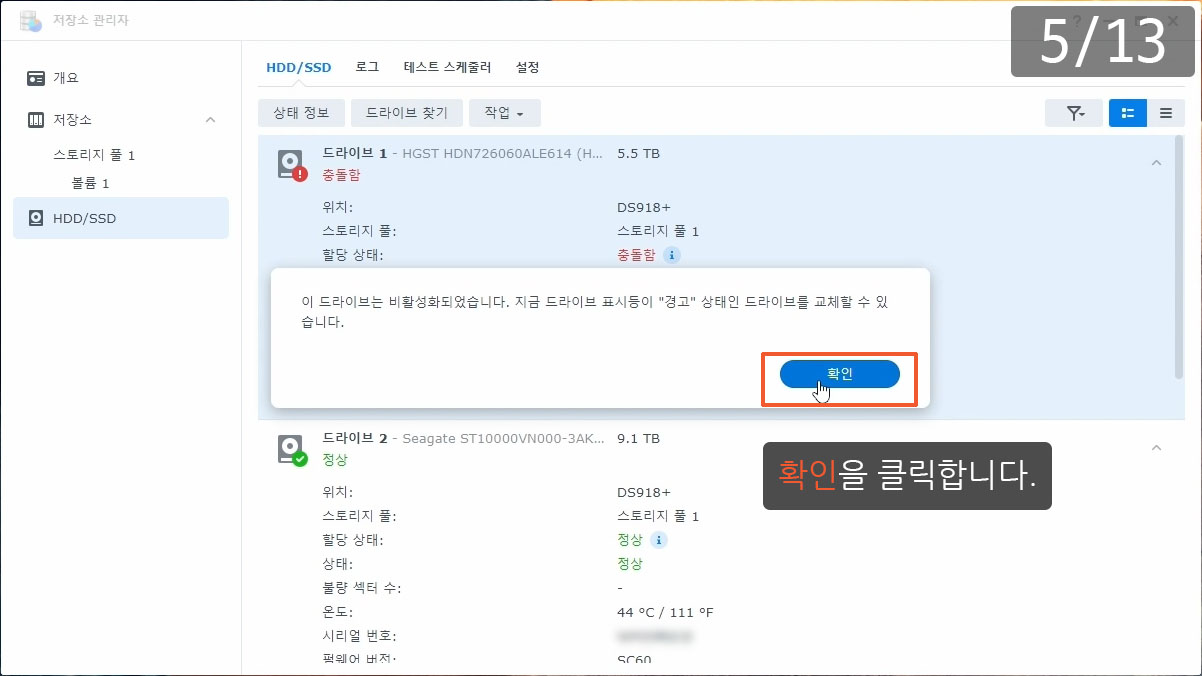
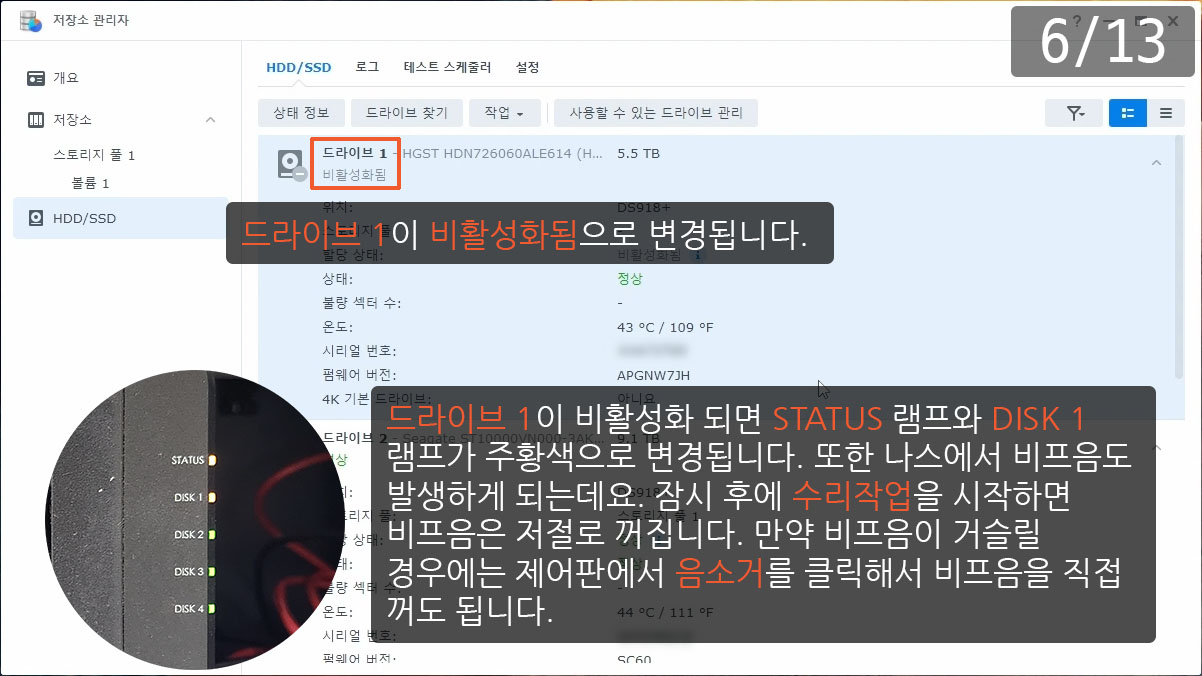
| 정보 | 시스템 | 2022/09/07 11:54:19 | admin | ①Drive (SN:K1K7ZXXX) has been deactivated. |
| 오류 | 시스템 | 2022/09/07 11:54:17 | SYSTEM | ②Storage Pool [1] degrade [3/4], please repair it. |
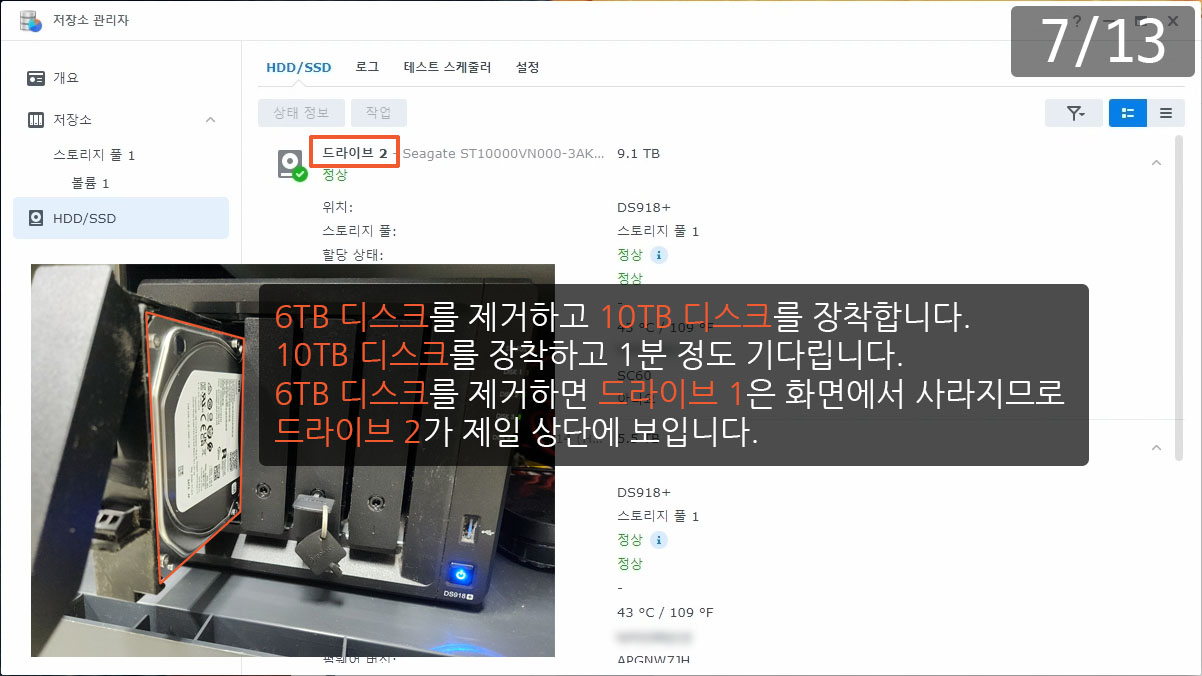
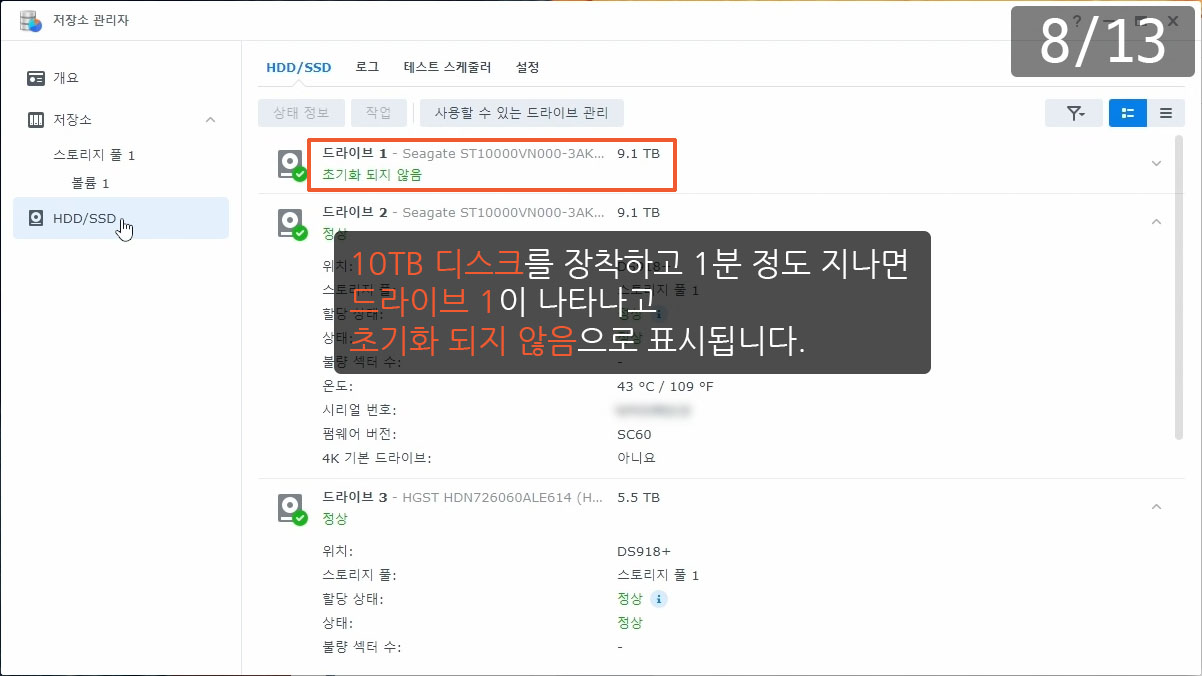
| 정보 | 시스템 | 2022/09/07 00:53:19 | admin | ④System successfully repaired [Storage Pool 1] with drive [Drive 3]. |
| 정보 | 시스템 | 2022/09/06 14:19:32 | admin | ③System started to repair [Storage Pool 1] with [Drive 3]. |
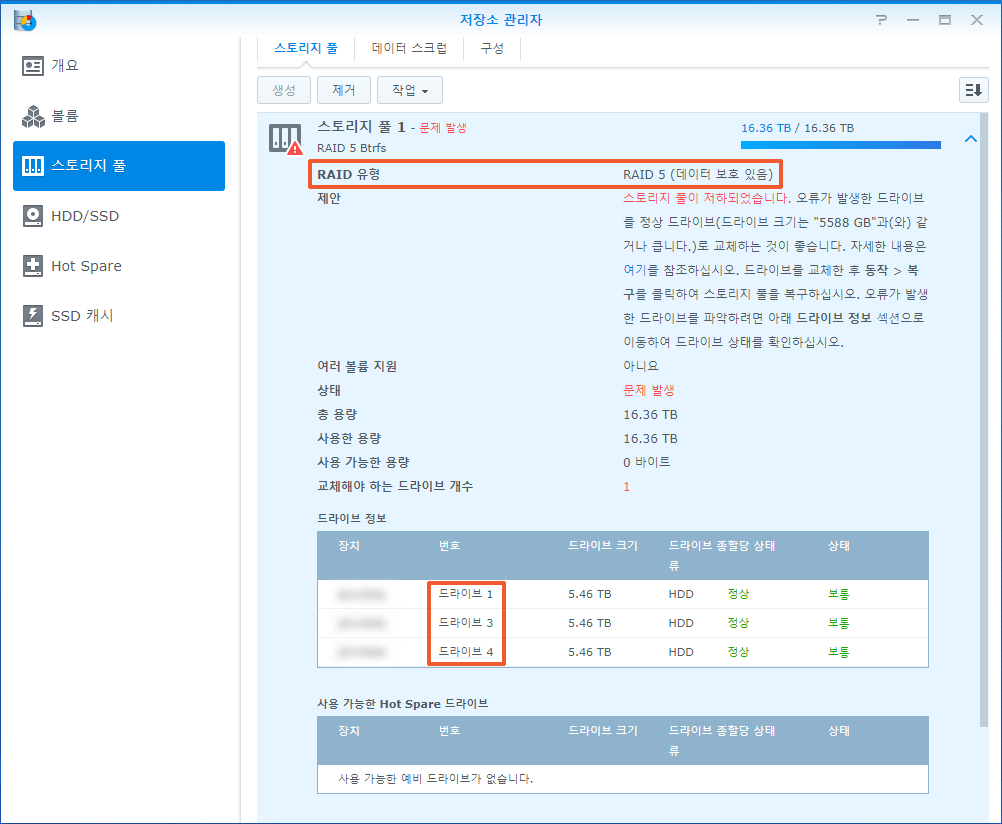
| 오류 | 시스템 | 2022/09/06 14:15:35 | SYSTEM | ②Storage Pool [1] degrade [3/4], please repair it. |
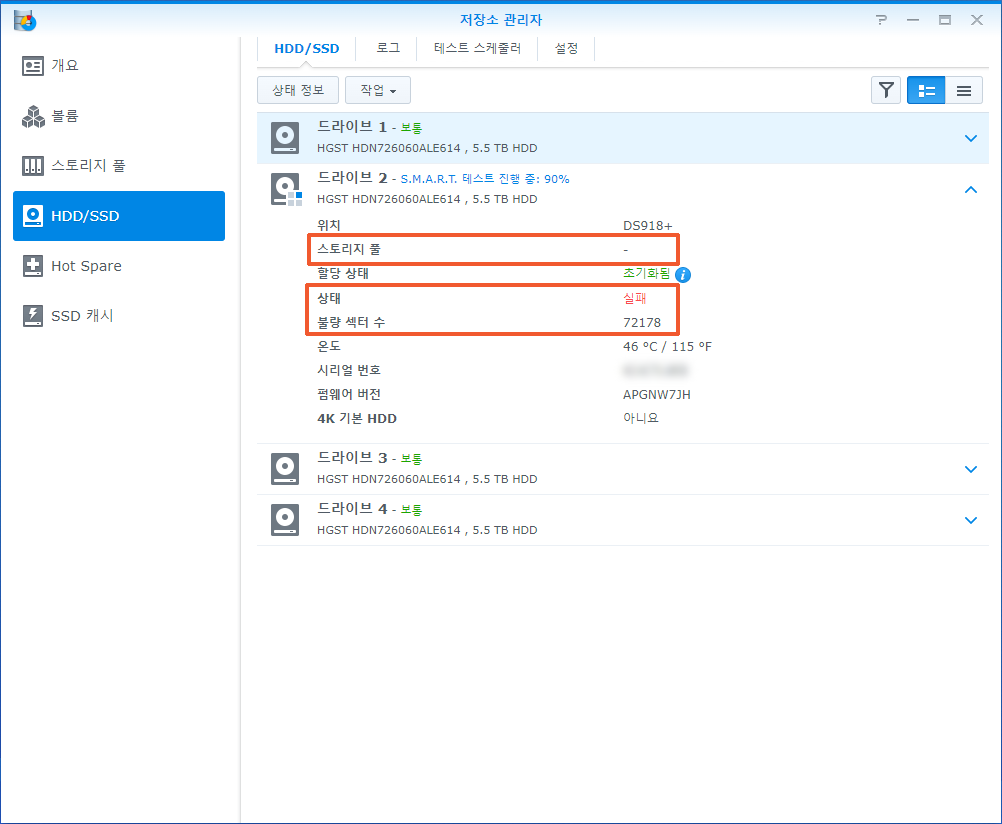
| 정보 | 시스템 | 2022/09/06 14:15:34 | admin | ①Drive (SN:K1K7MXXX) has been deactivated. |
| 정보 | 시스템 | 2022/09/05 22:36:59 | admin | ④System successfully repaired [Storage Pool 1] with drive [Drive 1]. |
| 정보 | 시스템 | 2022/09/05 11:13:05 | admin | ③System started to repair [Storage Pool 1] with [Drive 1]. |
| 오류 | 시스템 | 2022/09/05 11:10:11 | SYSTEM | ②Storage Pool [1] degrade [3/4], please repair it. |
| 정보 | 시스템 | 2022/09/05 11:10:11 | admin | ①Drive (SN:K1K7LXXX) has been deactivated. |
| 정보 | 시스템 | 2022/09/03 01:56:58 | admin | ④System successfully repaired [Storage Pool 1] with drive [Drive 2]. |
| 정보 | 시스템 | 2022/09/02 15:11:35 | admin | ③System started to repair [Storage Pool 1] with [Drive 2]. |
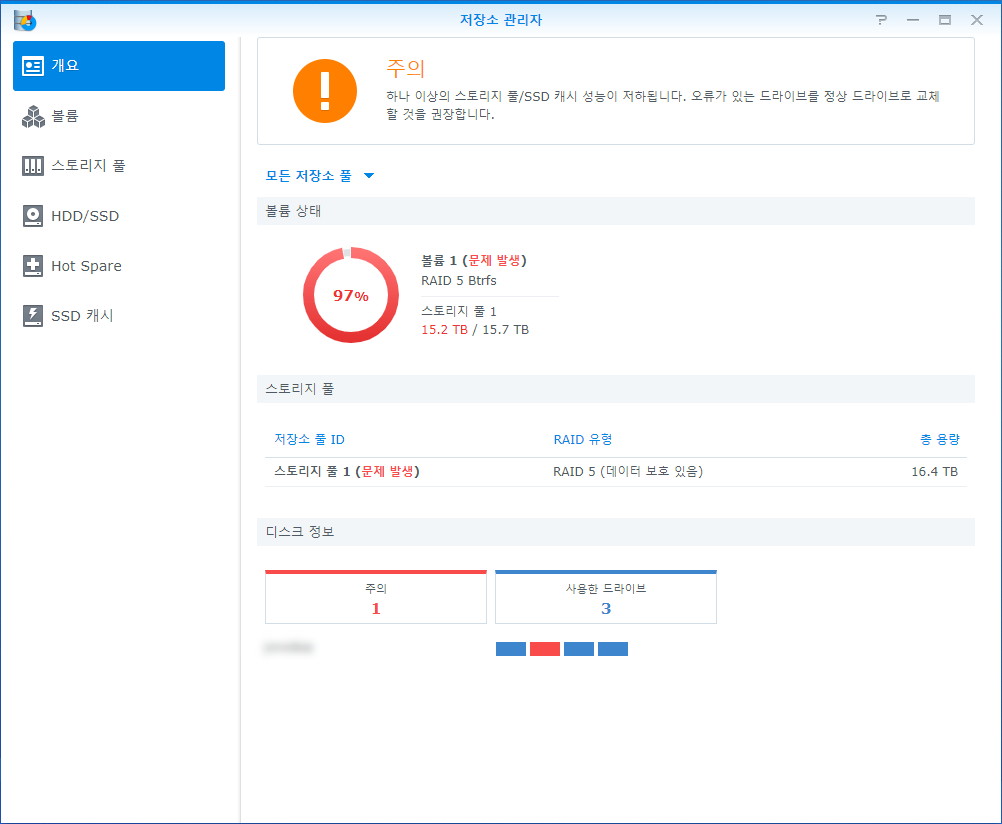
| 오류 | 시스템 | 2022/08/30 09:33:03 | SYSTEM | ②Storage Pool [1] was degrade [3/4], please repair it. |
| 오류 | 시스템 | 2022/08/29 12:01:40 | SYSTEM | Read error at internal disk [2] sector 4152924288. |
| 오류 | 시스템 | 2022/08/29 12:01:40 | SYSTEM | Write error at internal disk [2] sector 9439240. |

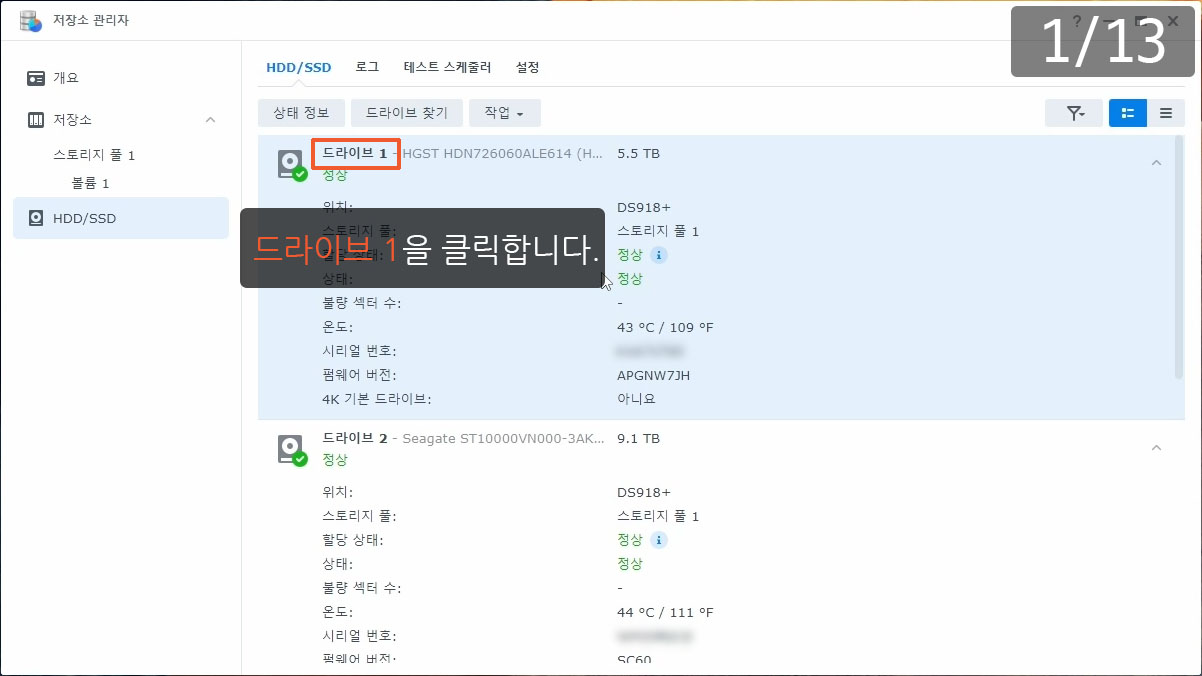
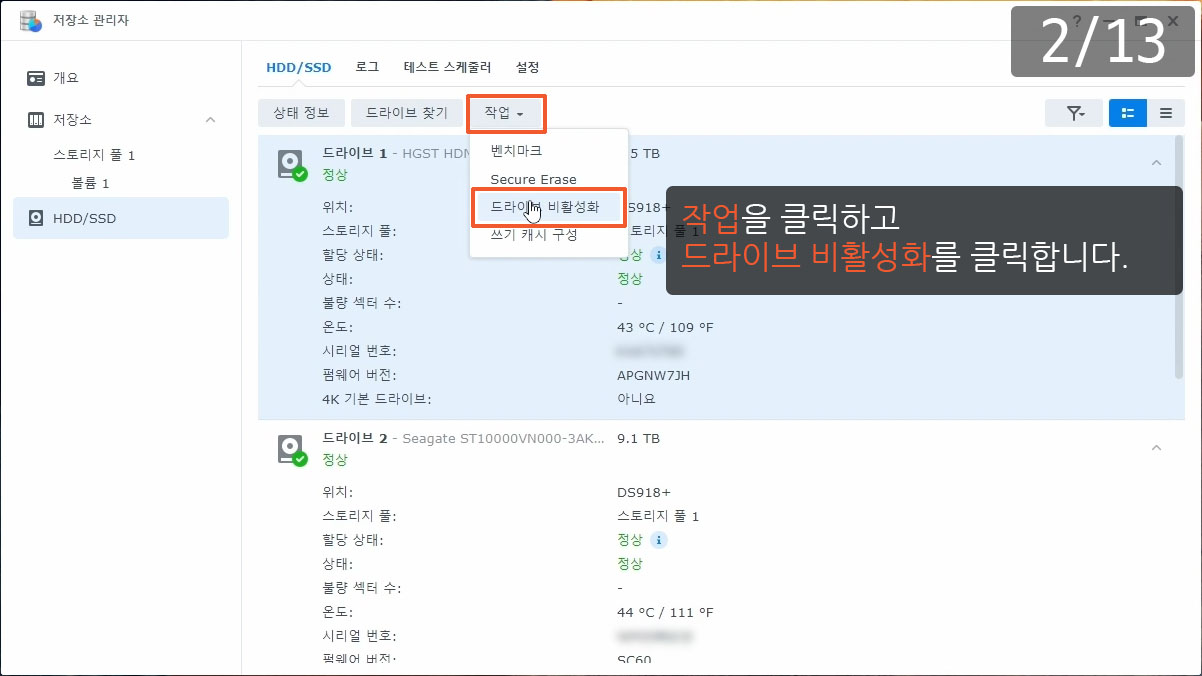
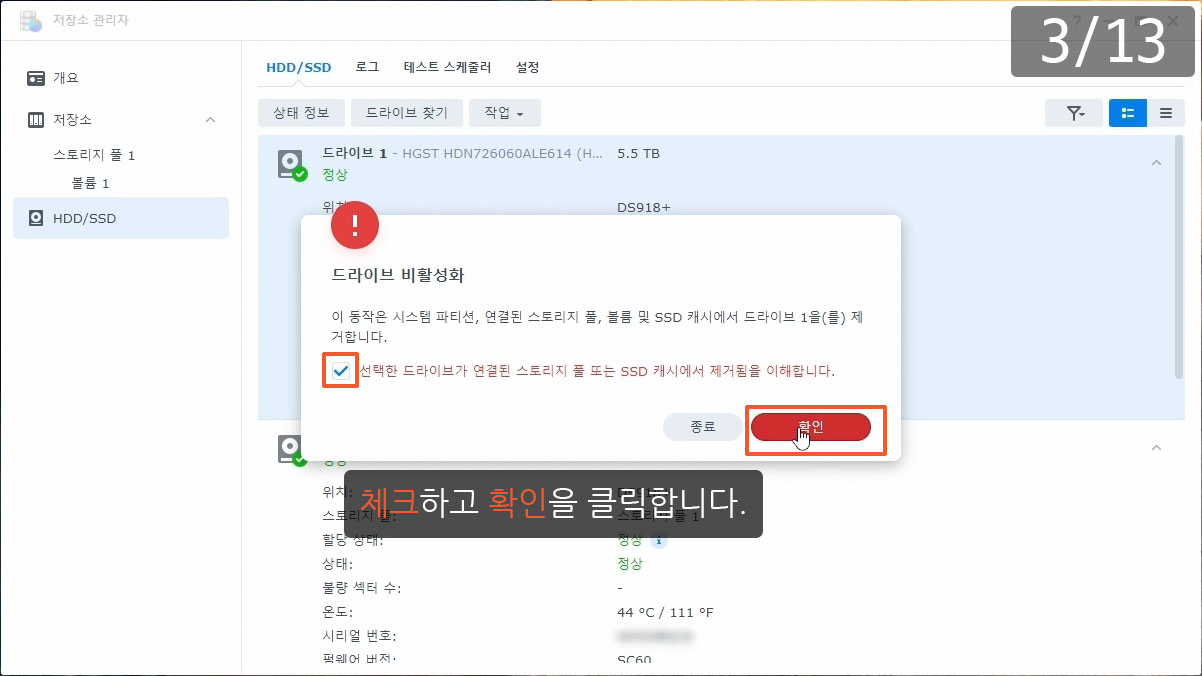
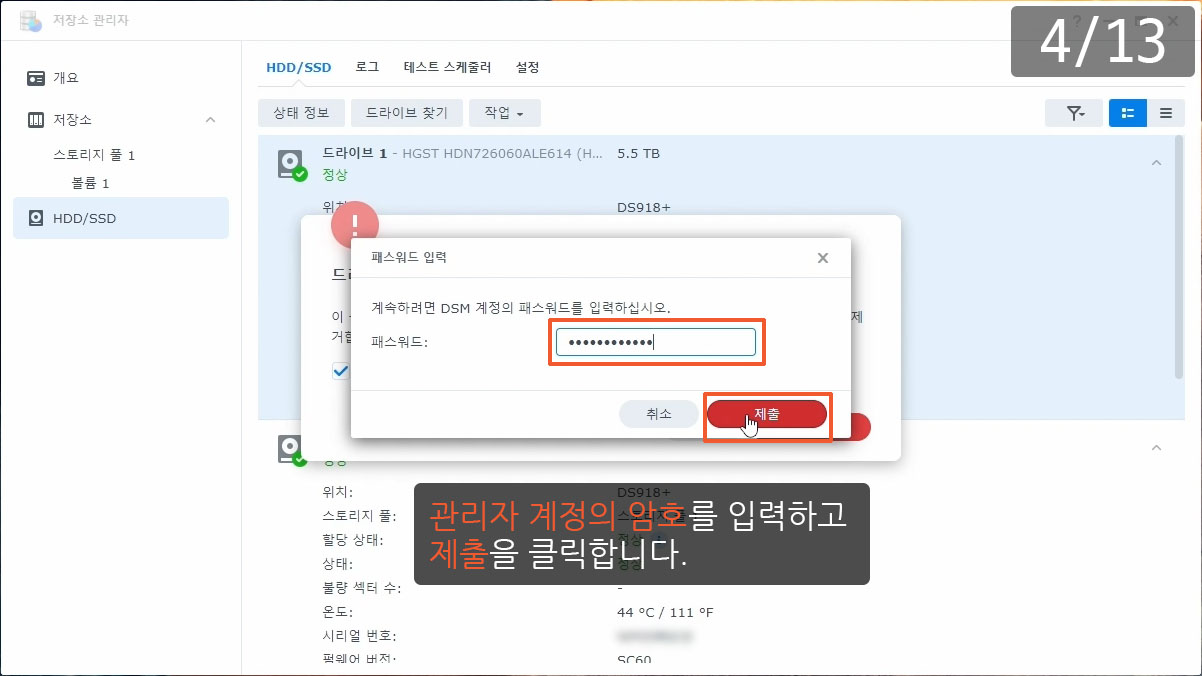
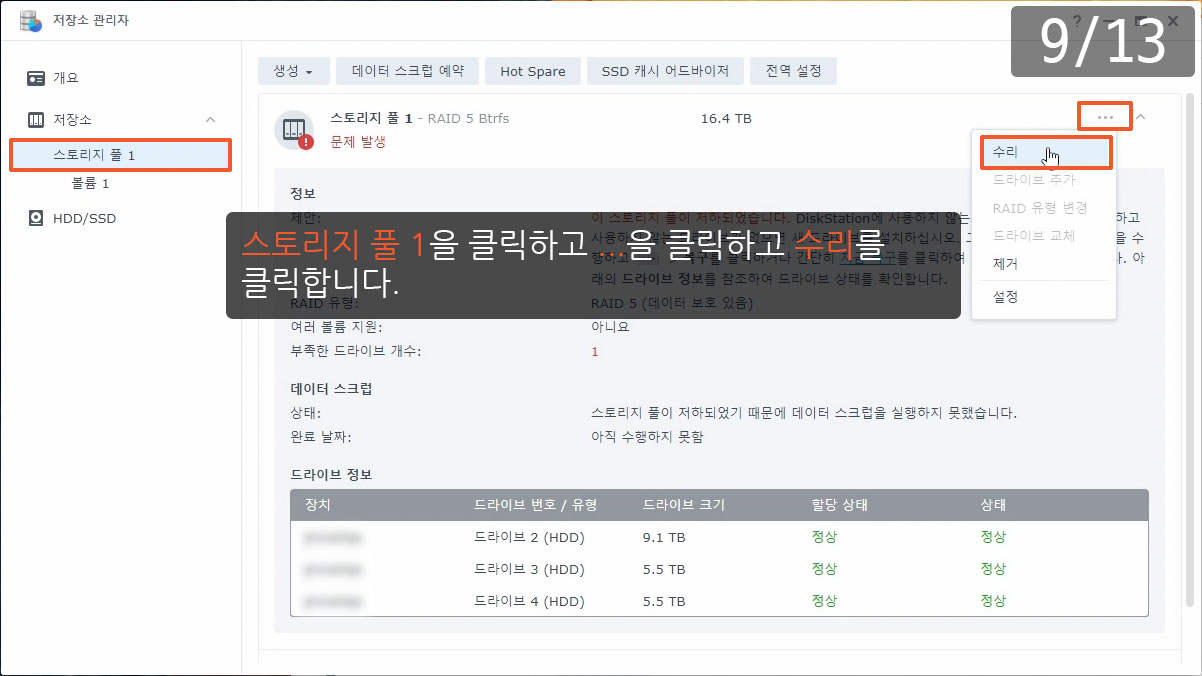
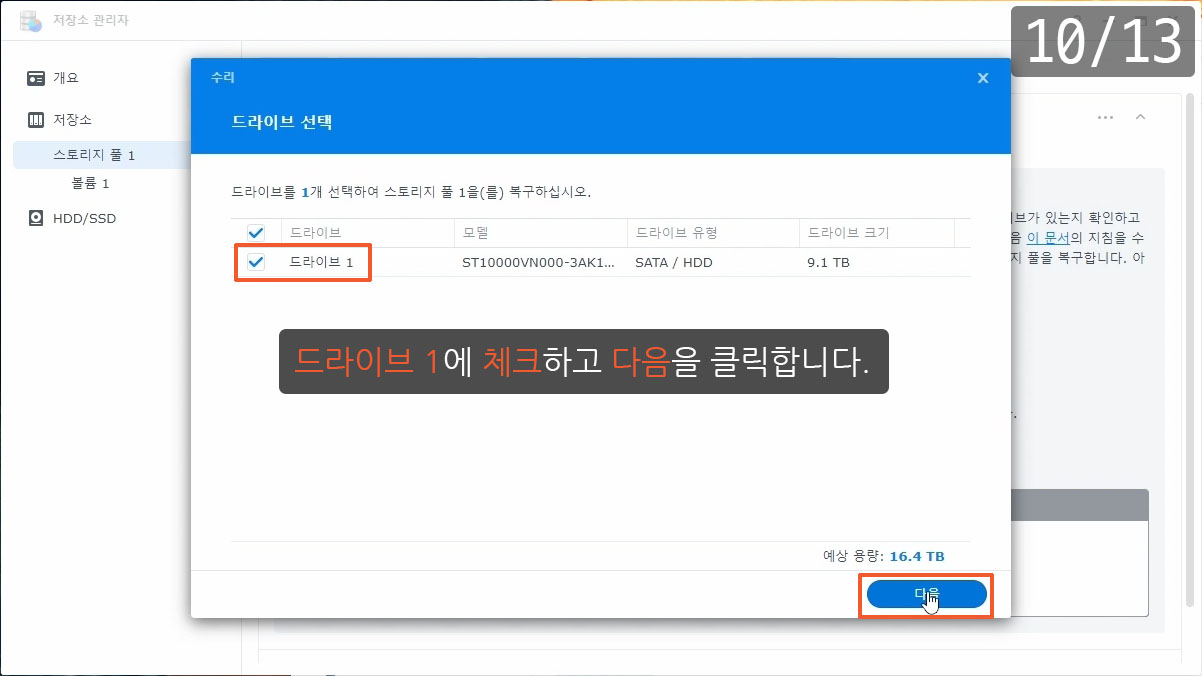
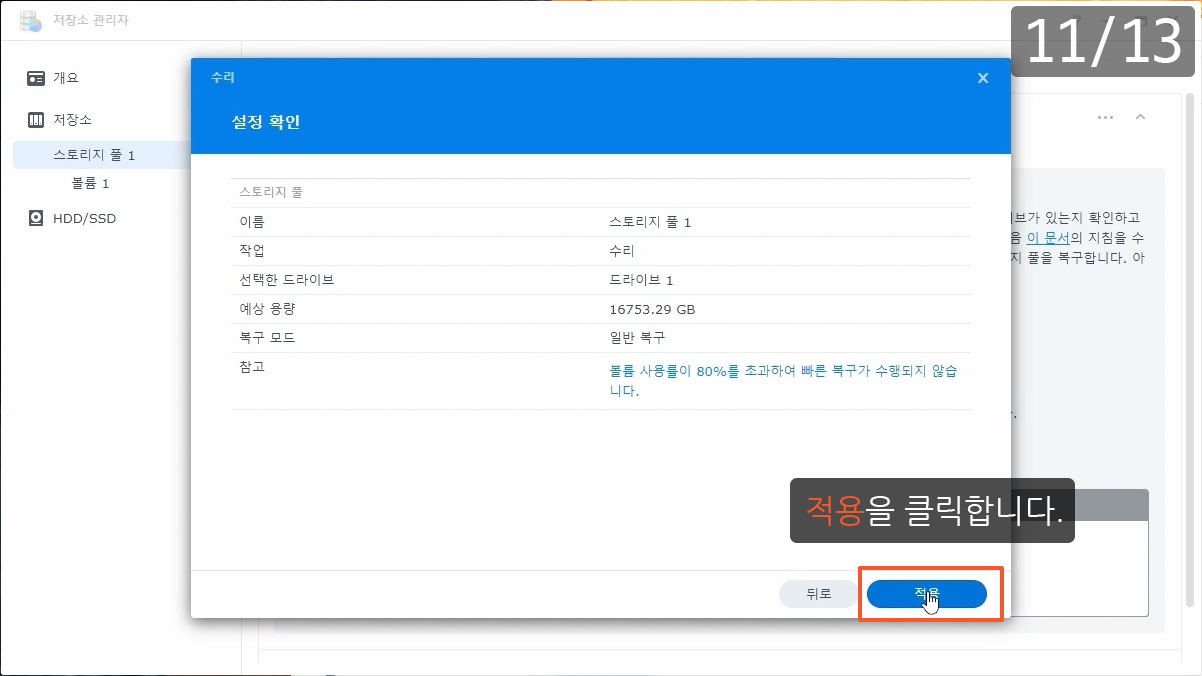
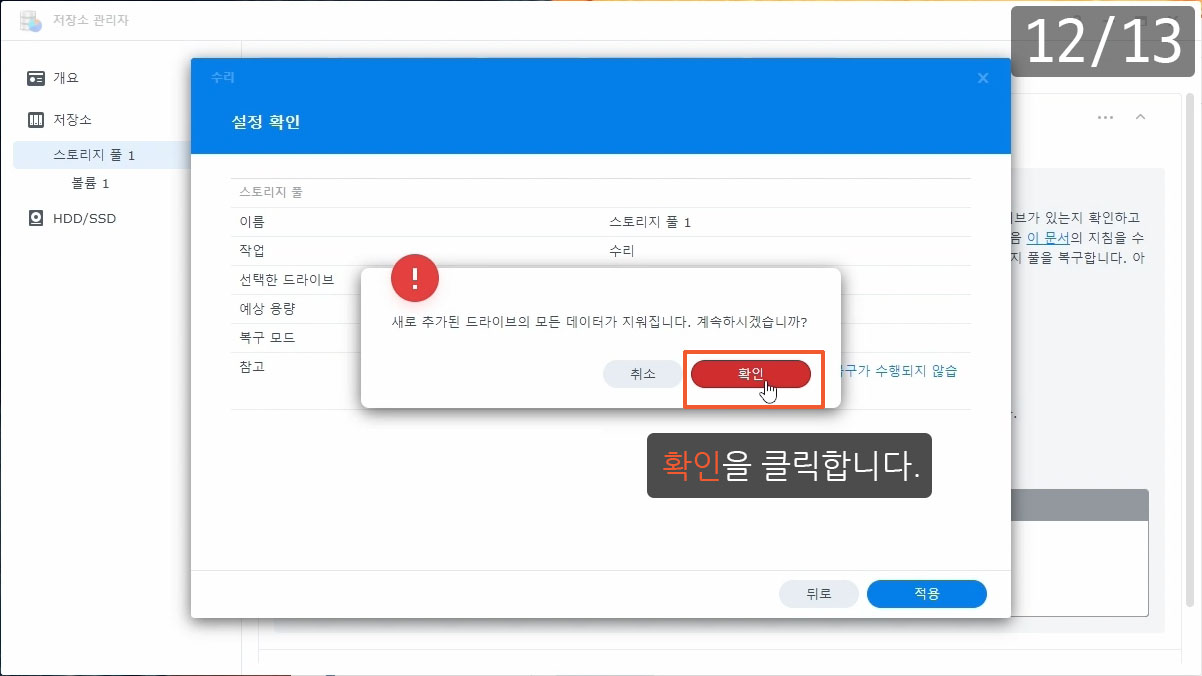


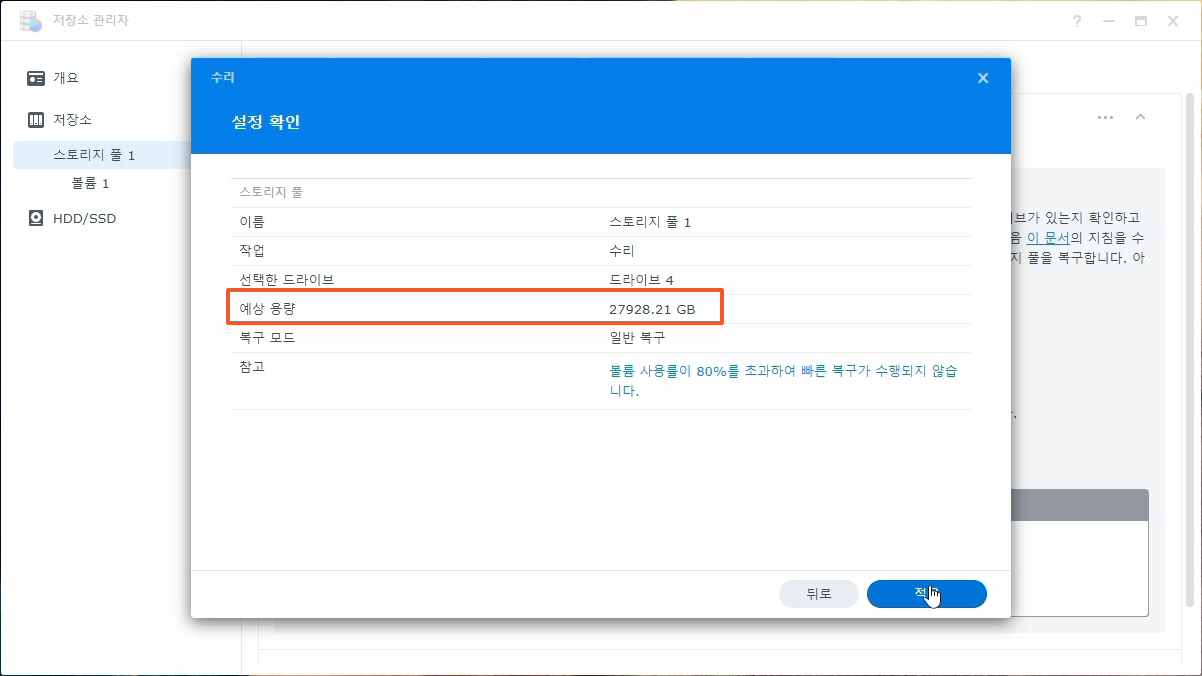
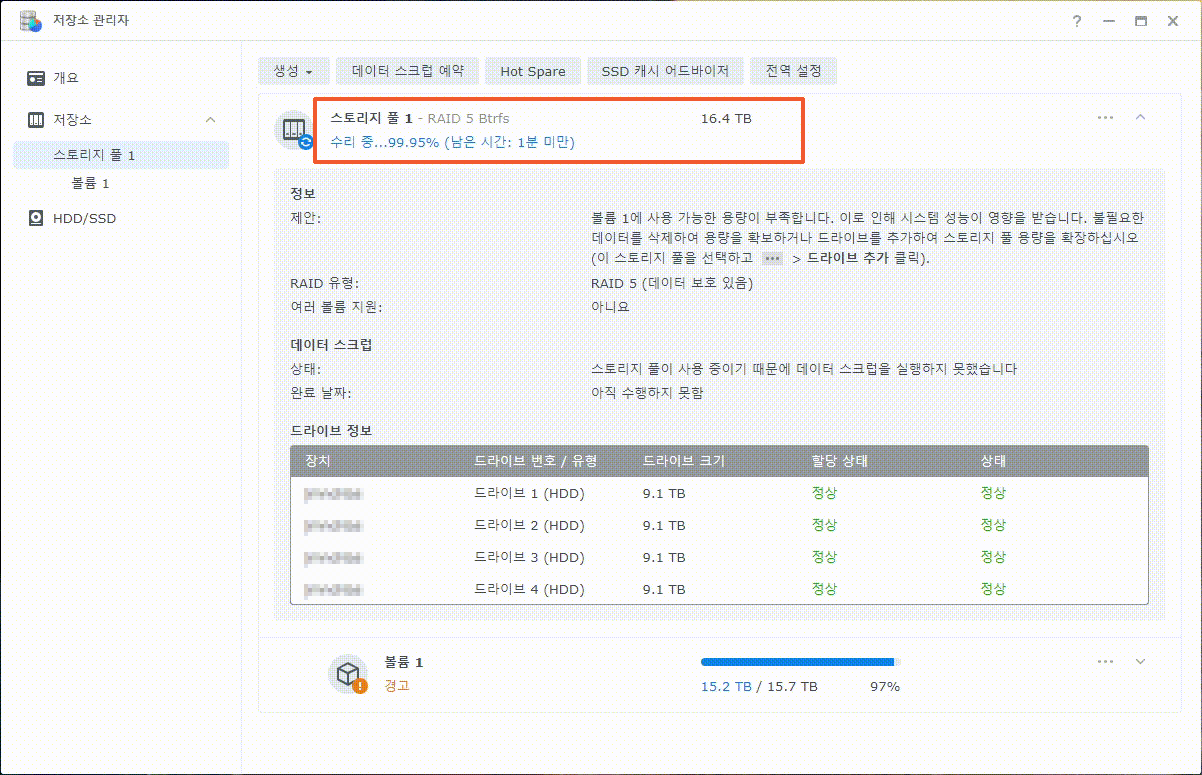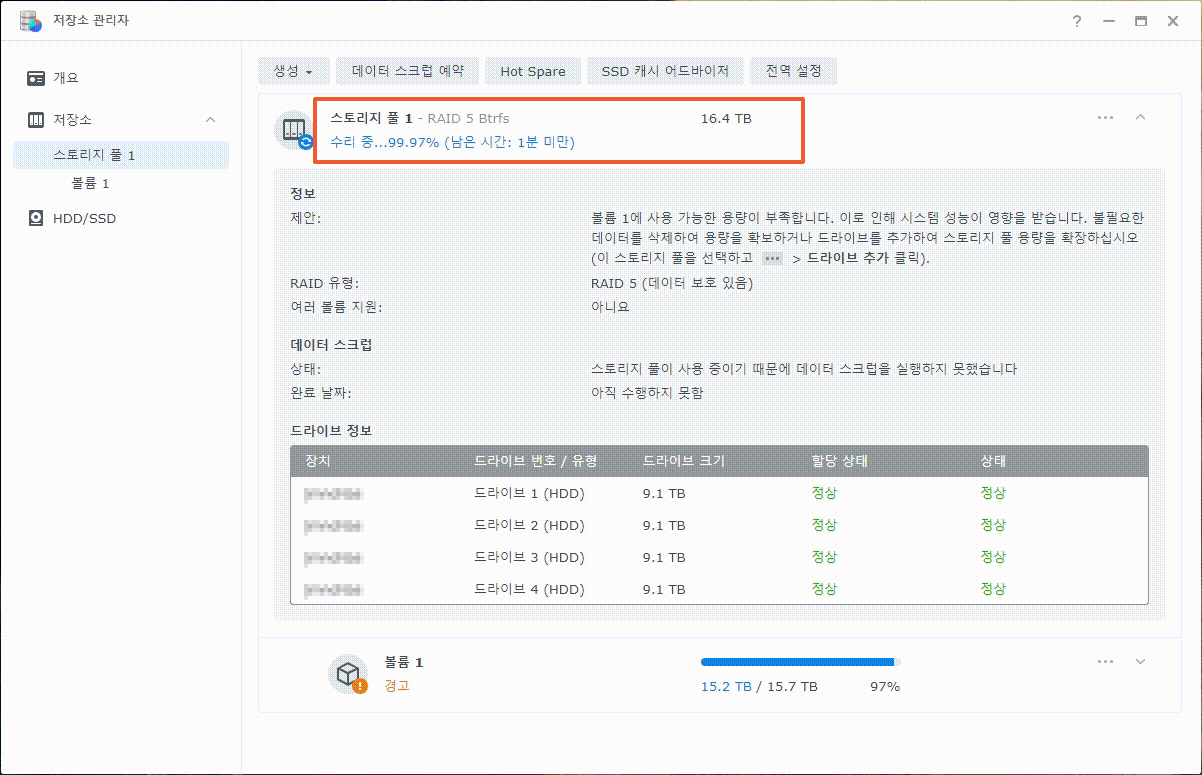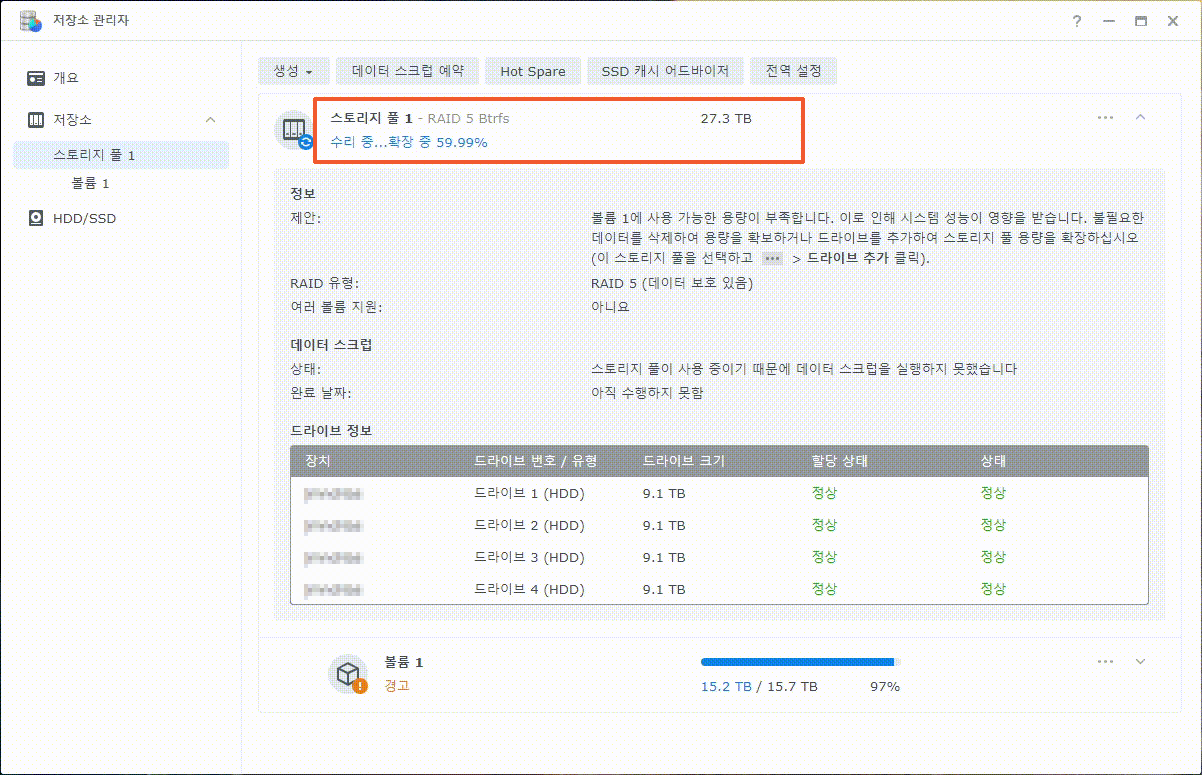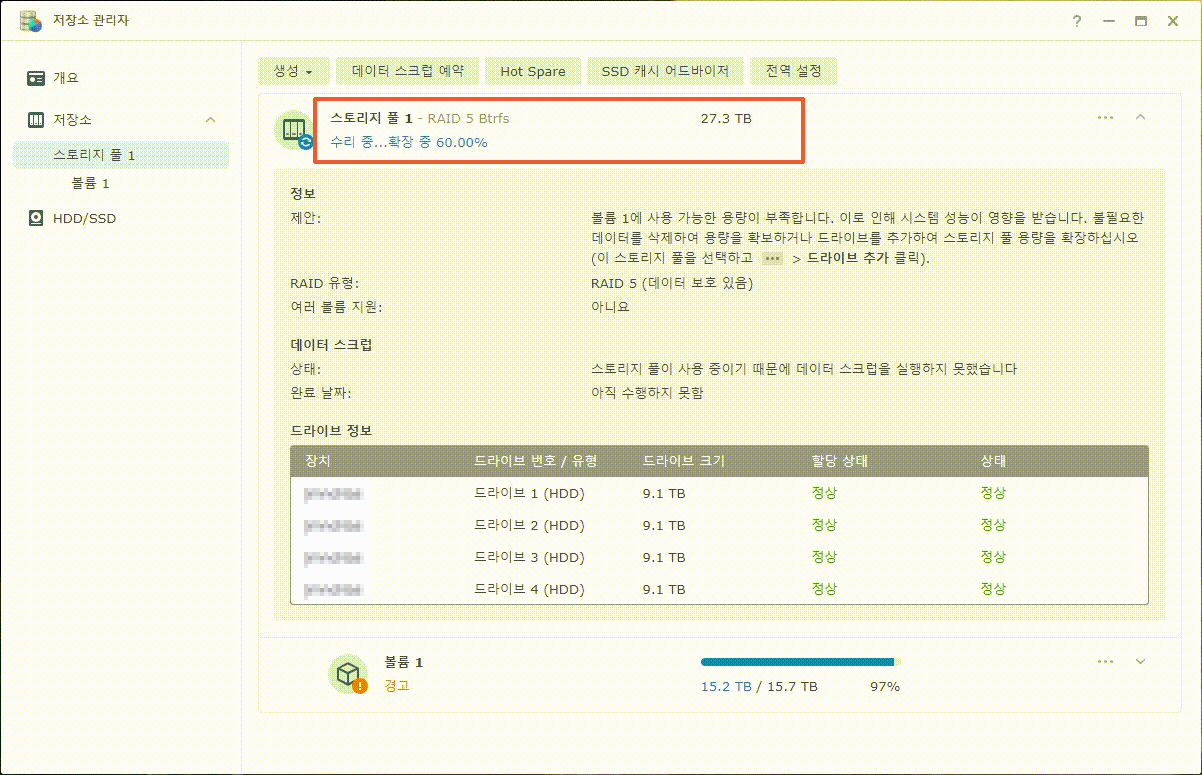
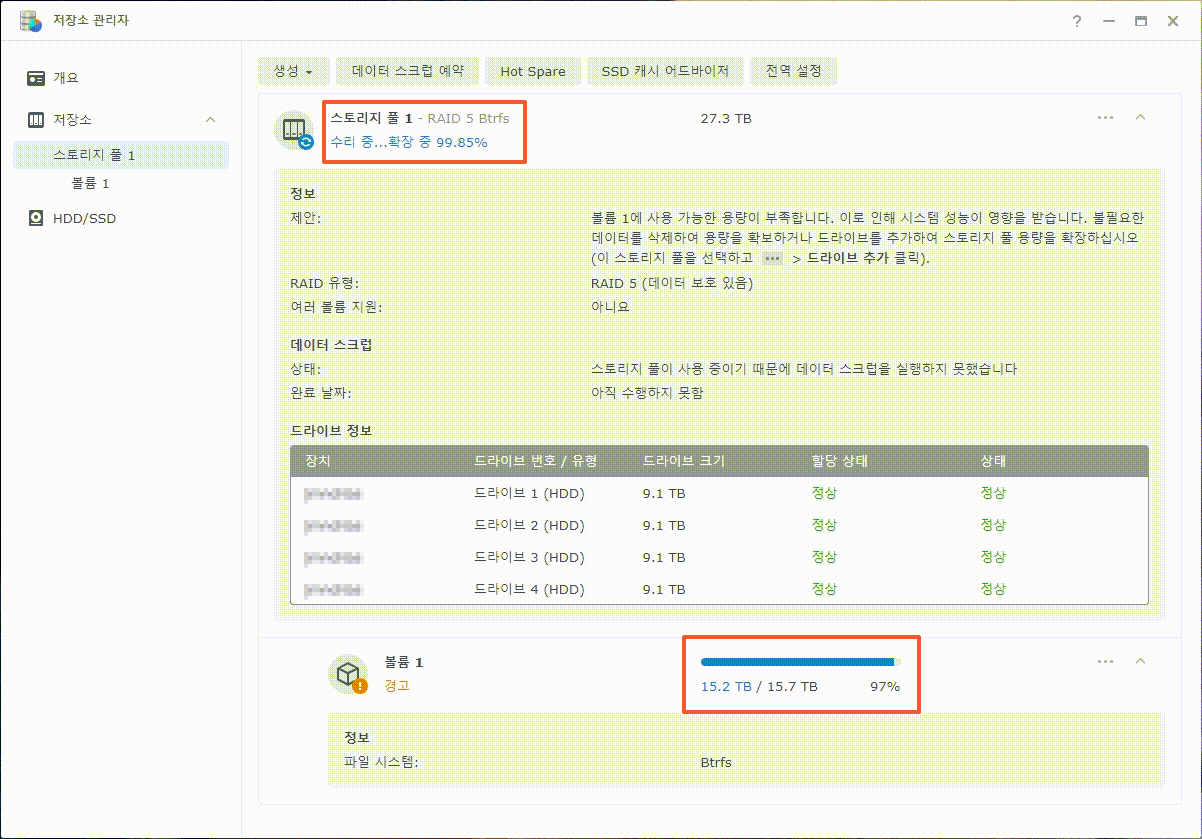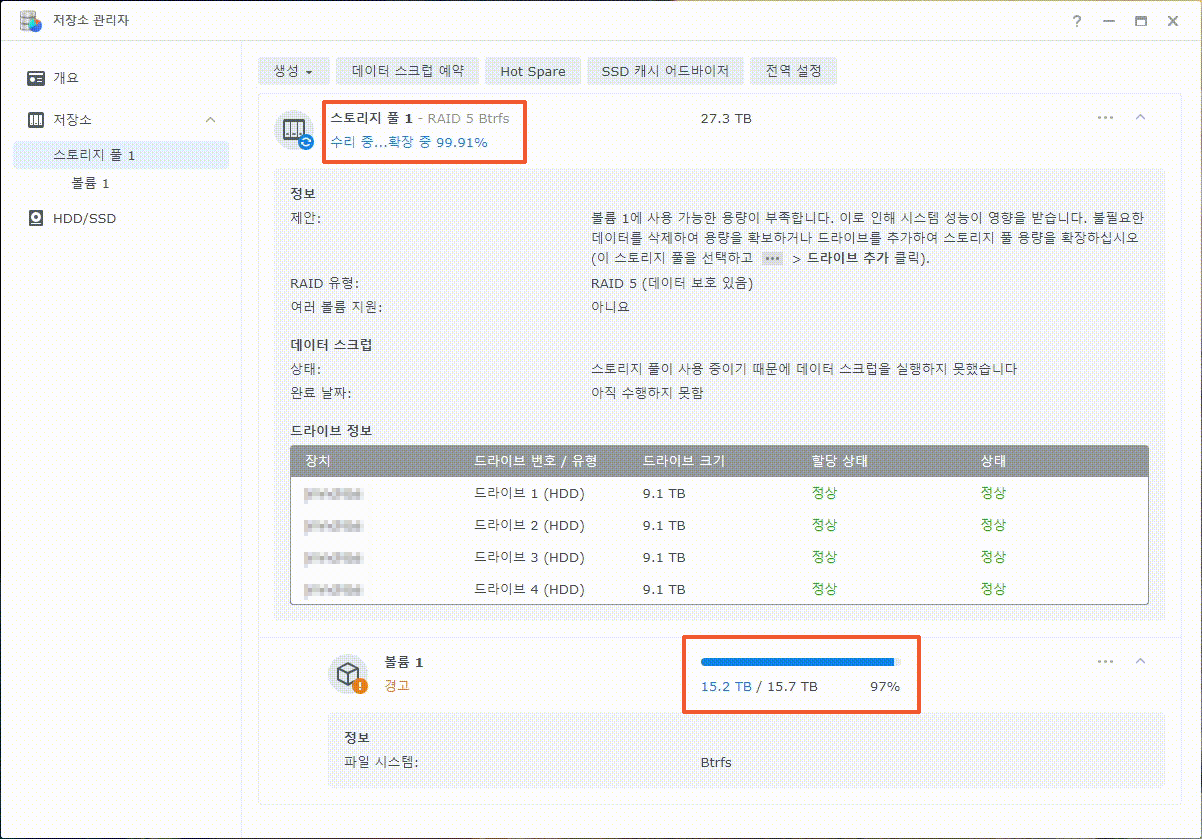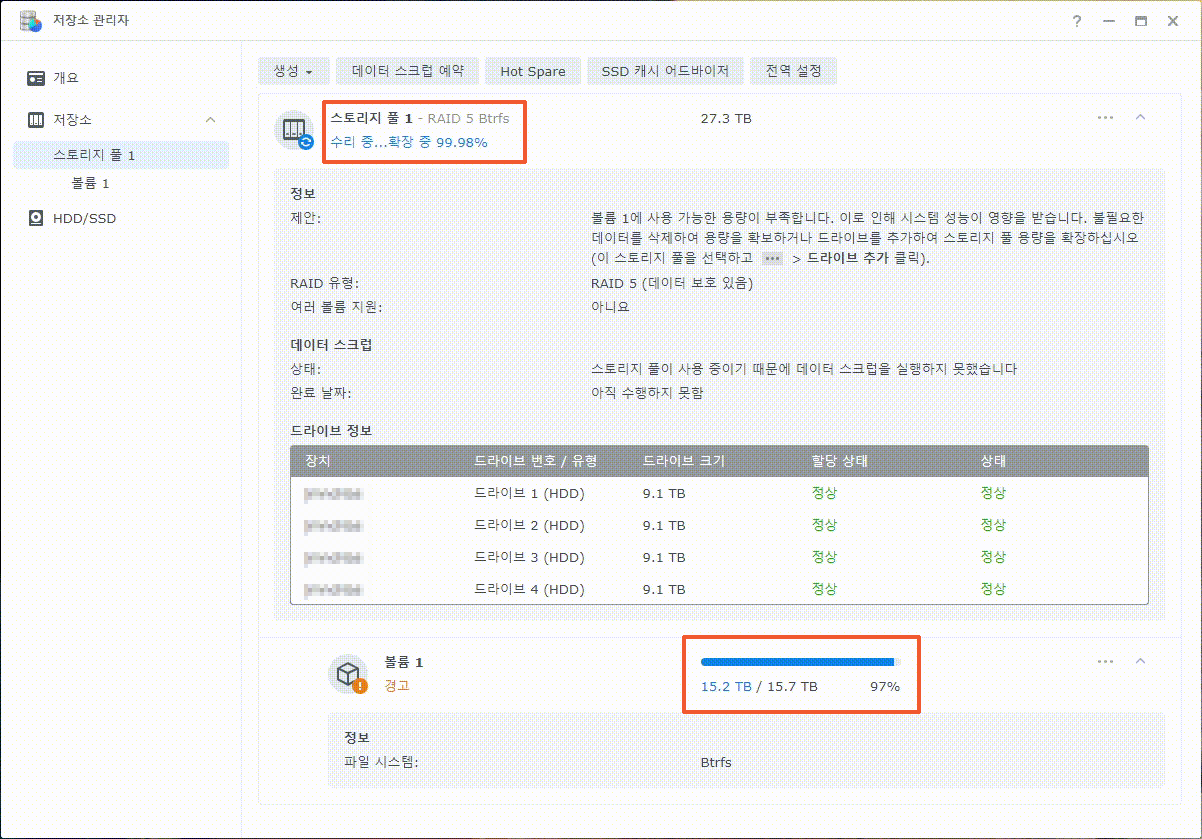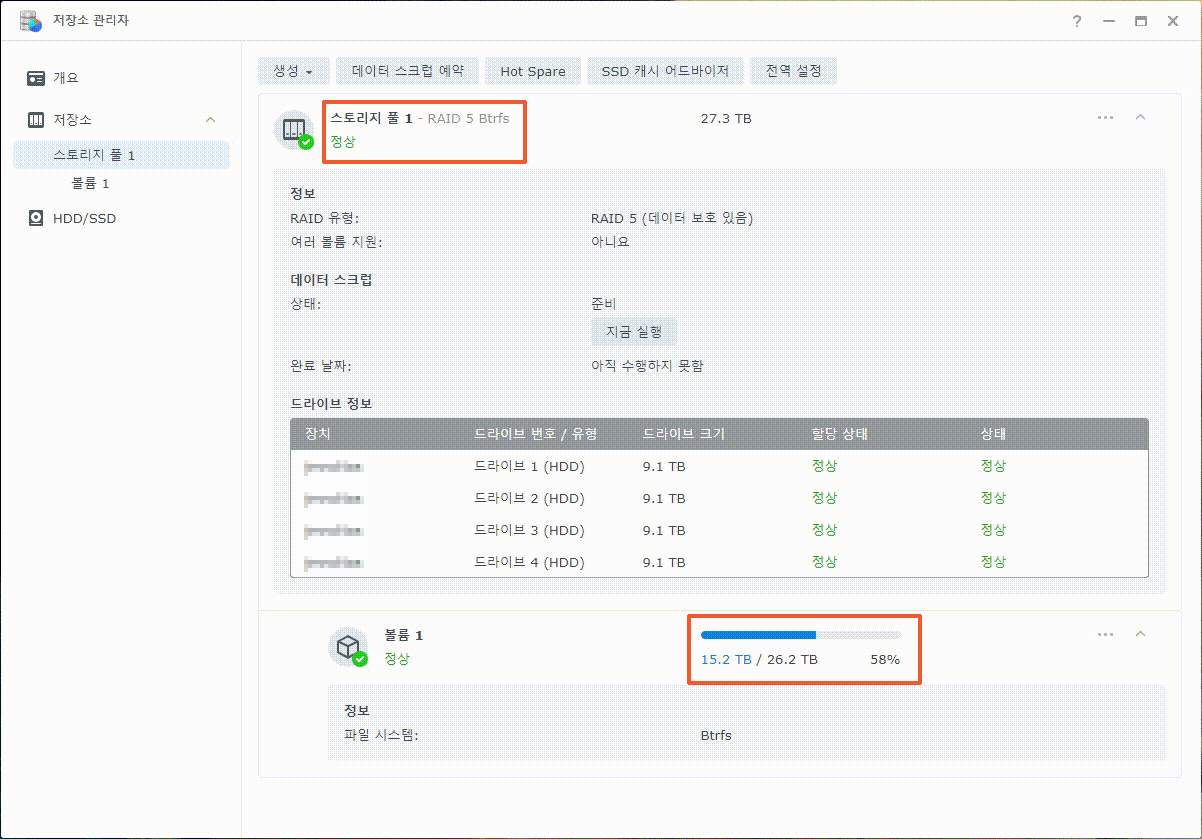



이제까지 본 하드교체를 통한 나스용량확장 관련 글이나 영상 중 제일 정확하고 자세합니다.
특시 스포리지의 확장 이후 볼륨확장까지 소요시간이 걸린다는 내용의 안내는 처음 본 것 같습니다.
쓰신 분의 정성과 노력이 보이는 내용이라 감사의 답글 올립니다.
감사합니다. 유익하게 보셨다니 뿌듯하네요.